Deteksi Penyakit Diabetes dengan Logistic Regression
Mempelajari bagaimana algoritma Logistic Regression dapat digunakan untuk mendeteksi kemungkinan diabetes berdasarkan data kesehatan pasien. Proyek ini cocok untuk skripsi, tugas akhir, dan pembelajaran machine learning bersama ITS Academics.

Pendahuluan
Deteksi dini terhadap penyakit diabetes menjadi sangat penting mengingat dampaknya yang besar terhadap kualitas hidup pasien. Salah satu pendekatan yang dapat digunakan adalah pemodelan statistik berbasis machine learning, khususnya menggunakan algoritma Logistic Regression. Proyek ini mengaplikasikan metode tersebut untuk memprediksi apakah seseorang mengidap diabetes berdasarkan data medis.
Pendekatan ini sangat cocok dijadikan topik skripsi atau tugas akhir, terutama dengan dukungan platform seperti ITS Academics dan layanan jasa joki skripsi yang mempermudah proses analisis dan pelaporan.
Deskripsi Dataset
Dataset yang digunakan adalah Pima Indians Diabetes Dataset, terdiri dari 768 baris data dengan 8 fitur numerik dan 1 target biner:
| Fitur | Deskripsi |
|---|---|
| pregnancies | Jumlah kehamilan |
| glucose | Kadar glukosa darah |
| blood_pressure | Tekanan darah |
| skin_thickness | Ketebalan lipatan kulit |
| insulin | Kadar insulin |
| BMI | Indeks massa tubuh (kg/m^2) |
| diabetes_pedigree | Riwayat diabetes dalam keluarga |
| age | Usia pasien |
| outcome | Label (1 = Diabetes, 0 = Tidak) |
Rumus Logistic Regression
Persamaan umum model regresi logistik adalah:
Dimana:
-
adalah fitur input
-
adalah koefisien model yang dipelajari dari data
-
Output adalah probabilitas dari kelas positif (diabetes)
Implementasi Python dengan Logistic Regression
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# Load dataset
df = pd.read_csv('https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv',
names=['pregnancies', 'glucose', 'blood_pressure', 'skin_thickness', 'insulin', 'BMI',
'diabetes_pedigree', 'age', 'outcome'])
# Fitur dan target
X = df.drop('outcome', axis=1)
y = df['outcome']
# Preprocessing
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split data
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# Inisialisasi dan training model
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# Prediksi dan evaluasi
y_pred = model.predict(X_test)
print("Akurasi:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
Analisis dan Interpretasi
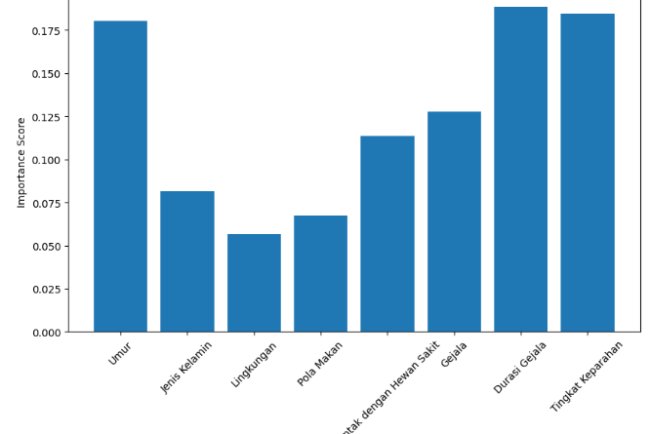
Hasil dari model menunjukkan bahwa fitur glucose, BMI, dan age memiliki kontribusi paling tinggi terhadap kemungkinan seseorang menderita diabetes. Logistic Regression juga memberikan probabilitas klasifikasi yang bisa dimanfaatkan untuk thresholding diagnosis klinis.
Visualisasi Korelasi Fitur
plt.figure(figsize=(10, 6))
sns.heatmap(df.corr(), annot=True, cmap="coolwarm")
plt.title("Korelasi Antar Variabel - Dataset Diabetes")
plt.show()
Kesimpulan
Logistic Regression adalah metode klasifikasi biner yang sederhana namun efektif, sangat cocok untuk mendeteksi penyakit seperti diabetes. Proyek ini relevan sebagai topik skripsi, tugas akhir, maupun studi kasus edukatif dalam bidang machine learning medis. Dengan bantuan ITS Academics dan jasa joki skripsi, mahasiswa dapat mengembangkan proyek ini menjadi solusi nyata berbasis data science yang aplikatif.
Apa Reaksi Anda?