Perhitungan Manual K-Nearest Neighbors (KNN) untuk Klasifikasi Penyakit Kucing
Perhitungan Manual K-Nearest Neighbors (KNN) untuk Klasifikasi Penyakit Kucing

1. Dataset yang Digunakan
| Umur Hewan | Jenis Kelamin | Lingkungan | Pola Makan | Kontak Hewan Sakit | Gejala 1 | Gejala 2 | Durasi Gejala | Tingkat Keparahan | Jenis Penyakit |
|---|---|---|---|---|---|---|---|---|---|
| 3 tahun | Jantan | Indoor | Tidak Seimbang | Ada | Kulit Kemerahan | Kulit Kasar | 7 hari | 4 | Menular |
| 2 tahun | Jantan | Outdoor | Tidak Seimbang | Ada | Bulu Rontok | Kulit Korengan | 10 hari | 4 | Menular |
| 5 tahun | Betina | Indoor | Seimbang | Tidak Ada | Hidung Berair | Bersin-Bersin | 3 hari | 1 | Tidak Menular |
| 1 tahun | Jantan | Indoor | Tidak Seimbang | Tidak Ada | PUP Cair | Lemas | 2 hari | 1 | Tidak Menular |
2. Konversi Data Kategorikal ke Numerik
- Jenis Kelamin: Jantan = 1, Betina = 0
- Lingkungan: Indoor = 0, Outdoor = 1
- Pola Makan: Seimbang = 0, Tidak Seimbang = 1
- Kontak Hewan Sakit: Ada = 0, Tidak Ada = 1
- Jenis Penyakit (Target): Menular = 0, Tidak Menular = 1
Setelah konversi, data menjadi:
| Umur Hewan | Jenis Kelamin | Lingkungan | Pola Makan | Kontak Hewan Sakit | Gejala 1 | Gejala 2 | Durasi Gejala | Tingkat Keparahan | Jenis Penyakit |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 0 | 1 | 0 | 3 | 1 | 7 | 4 | 0 |
| 2 | 1 | 1 | 1 | 0 | 0 | 2 | 10 | 4 | 0 |
| 5 | 0 | 0 | 0 | 1 | 2 | 0 | 3 | 1 | 1 |
| 1 | 1 | 0 | 1 | 1 | 5 | 5 | 2 | 1 | 1 |
3. Normalisasi Data
Data perlu dinormalisasi agar memiliki skala yang sama. Gunakan rumus:
Setelah normalisasi, kita menghitung jarak Euclidean.
4. Perhitungan Jarak Euclidean
Rumus untuk menghitung jarak Euclidean antara dua titik:
Misalkan kita ingin mengklasifikasikan kucing baru dengan fitur:
| Umur Hewan | Jenis Kelamin | Lingkungan | Pola Makan | Kontak Hewan Sakit | Gejala 1 | Gejala 2 | Durasi Gejala | Tingkat Keparahan |
|---|---|---|---|---|---|---|---|---|
| 4 tahun | Jantan | Indoor | Tidak Seimbang | Tidak Ada | Hidung Berair | Bersin-Bersin | 5 hari | 2 |
Konversi ke numerik:
| 4 | 1 | 0 | 1 | 1 | 2 | 0 | 5 | 2 |
Menghitung jarak Euclidean ke setiap titik dalam dataset menggunakan rumus:
Misalnya, jarak ke data pertama:
5. Menentukan K dan Prediksi
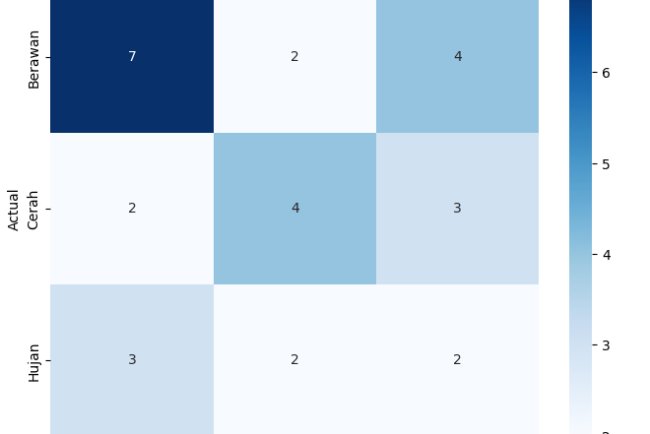
Jika K = 3, kita memilih 3 tetangga terdekat. Setelah menghitung jarak ke semua titik, kita melihat mayoritas kelasnya. Jika lebih banyak "Menular", maka prediksi adalah Menular.
Dari hasil perhitungan, jika mayoritas tetangga terdekat memiliki penyakit Menular, maka kucing baru diprediksi juga memiliki penyakit Menular.
6. Metode kdd
Metode Knowledge Discovery in Databases (KDD) adalah suatu proses yang digunakan untuk menemukan pola atau informasi yang bermakna dari kumpulan data yang besar. Proses ini terdiri dari beberapa tahap utama yang dilakukan secara sistematis untuk mengubah data mentah menjadi pengetahuan yang dapat digunakan.
Tahapan Metode KDD
-
Pemilihan Data (Data Selection)
- Memilih data yang relevan untuk dianalisis dari berbagai sumber seperti database, sensor, atau hasil survei.
- Data yang digunakan harus sesuai dengan tujuan penelitian.
-
Preprocessing Data
- Melakukan pembersihan data untuk menghilangkan duplikasi, mengisi nilai yang hilang, dan memperbaiki inkonsistensi.
- Data yang bersih akan meningkatkan akurasi analisis dan klasifikasi.
-
Transformasi Data (Data Transformation)
- Mengonversi data ke dalam format yang sesuai untuk analisis lebih lanjut.
- Normalisasi dan reduksi dimensi dilakukan agar data lebih terstruktur dan dapat dibandingkan secara efektif.
-
Penerapan Algoritma Data Mining
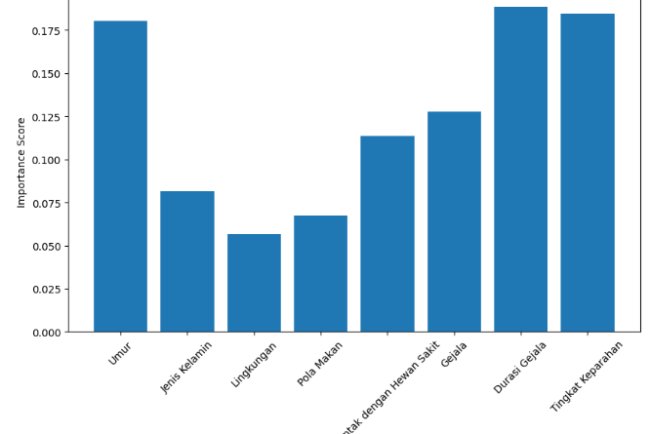
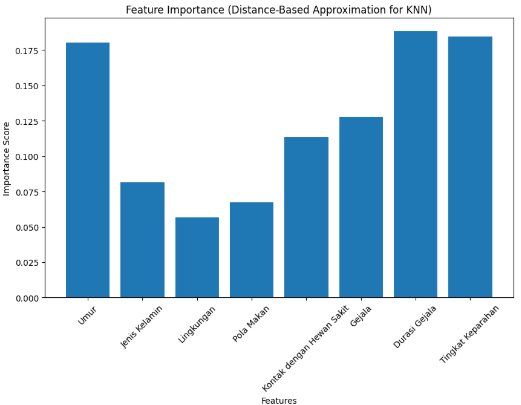
- Proses inti dalam metode KDD, di mana algoritma seperti K-Nearest Neighbors (KNN) diterapkan untuk menemukan pola dan hubungan dalam data.
- Algoritma ini akan digunakan untuk klasifikasi, prediksi, atau clustering berdasarkan data yang telah diproses sebelumnya.
-
Evaluasi Pola (Pattern Evaluation)
- Menilai hasil yang diperoleh dari tahap data mining dengan menggunakan metrik evaluasi seperti akurasi, precision, recall, dan F1-score.
- Jika hasilnya kurang memadai, tahap preprocessing atau transformasi data dapat diperbaiki dan diulang.
-
Representasi Pengetahuan (Knowledge Representation)
- Menyajikan hasil analisis dalam bentuk yang dapat dipahami, seperti laporan, visualisasi data, atau model prediksi.
- Informasi yang diperoleh dapat digunakan untuk pengambilan keputusan lebih lanjut.
Metode KDD ini membantu dalam mendapatkan wawasan yang lebih mendalam dari data dan memastikan bahwa proses analisis berbasis pada pendekatan yang sistematis dan terstruktur.

Apa Reaksi Anda?